Greenplum 5.0.0 brought us a lot of new features. Most of them were planned a long time ago, but couldn’t be implemented without breaking backward binary compatibility, which cannot be done in 4.X major branch.
One of such features is a new PXF framework. It allows you to integrate Greenplum cluster with other systems – databases, in-memory grids, Hadoop components, etc. Moreover, it can do it in parallel – all Greenplum segments can retrieve its personal shards of data.
Theory
PXF is an extensible framework that allows Greenplum to interact with external systems. In fact, PXF is a server process on one or more hosts that works with Greenplum’s segments via REST API, along with this interactingwith external systems via their own Java API.
PXF is not a new technology – earlier it was used in Hawq – Greenplum clone (fork), running on Hadoop ecosystem (think of it like Greenplum running on HDFS instead of local segment file systems).
To use the power of MPP, we need to use multiple PXF server processes per Greenplum instance, so for now the best solution is to use one PXF process per Greenplum server (not logical segment).
 A common interaction process between Greenplum and PXF looks like this:
A common interaction process between Greenplum and PXF looks like this:
- A user runs a query on GP master that retrieves data from PXF’s external table.
- The master reads external table LOCATION clause and pushes segments to make a query to PXF server.
- All GP segments construct REST query (it can contain external source type, DB host, username, password, data distribution parameters and so on) and push it to PXF via REST API. Notice that PXF host and port are the same on all of the segments – localhost:51200.
- PXF accepts REST query from the segment (every segment query creates an independent thread inside the PXF server), parses it and accesses the external system via three system-specific Java classes: Accessor, Fragmenter and Resolver. Additional information about Java classes can be found here.
- PXF retrieves data from the external system and proxies it to GP segment via REST API.
At the time of writing this article, PXF supports four data source types: HDFS, Hive, Hbase – officially, and JDBC – in an experimental mode.
For example, communication process with HDFS will be the following:
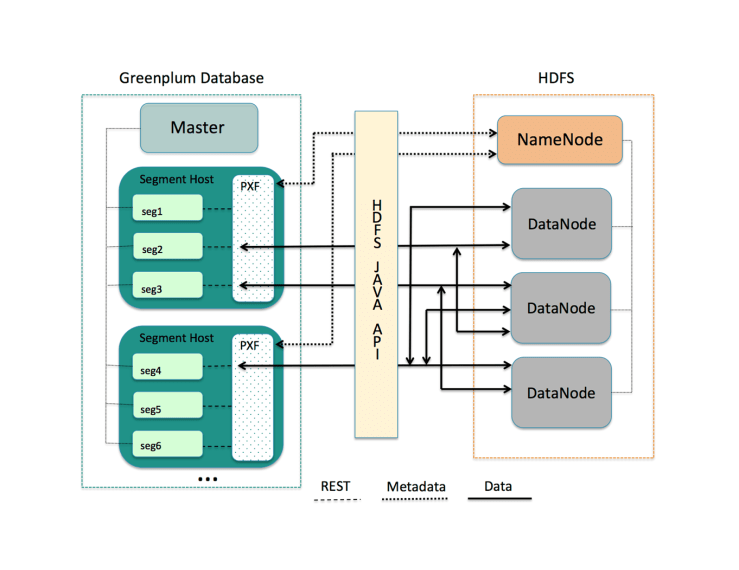
This scheme shows that PXF is able to work with distributed systems. Firstly, every PXF instance connects to a namenode of the cluster and gets a location of every shard of the data, and then retrieves shards of the data and proxies every shard to one of Greenplum segments.
Some data sources can also provide possibility to use user’s data sharding logic. For example, JDBC connector allows users to set the number of rows that every GP segment will retrieve from the source table in the external database (we will see this in the next chapter). This allows you to control the level of parallelizing of the data load.
Until the Greenplum’s minor version 5.3, Greenplum didn’t support user impersonation in PXF. Now Greenplum user maps to the external user directly For example, if you are accessing a JDBC table from the gpadmin user, there must be a gpadmin user in the external database and it’s password must be specified in the external table LOCATION clause. This behavior will be changed soon because of the lack of flexibility.
As for now, all PXF connectors, except HDFS connector, are read-only. I hope, soon we could see other connectors writable too.
Practice
Assume that you have Greenplum 5.3.0 cluster installed, initialized and running. Let’s build a PXF server, setup it to work with Hadoop cluster and run it. PXF server must be run on every Greenplum segment host.
# Install required packages
# Note that you need to install hadoop rpms specific to your
# Hadoop cluster (Cloudera, MapR, Horton, etc) and having same versions
yum install java-1.8.0-openjdk-devel hive hbase hadoop-client hadoop-hdfs hadoop-libhdfs git
# Create user and group for running pxf server
groupadd pxf
useradd -g pxf pxf
# Create and chown all required directories
mkdir /usr/lib/gpdb/pxf /var/log/pxf /var/run/pxf
#Create temporary folder for HAWQ sources
mkdir hawq
cd hawq
# Clone the HAWQ repo
git clone https://git-wip-us.apache.org/repos/asf/incubator-hawq.git
# Set the target directory
export PXF_HOME=/usr/lib/gpdb/pxf
# Build PXF
cd incubator-hawq/pxf
make install
# Chown installtion to pxf user
chown -R pxf:pxf /usr/lib/gpdb/pxf /var/log/pxf /var/run/pxf
# Copy the folowing config files from your Hadoop cluster to the PXF
# server host (every Greenplum segment host in our case):
# /etc/hadoop/conf/core-site.xml
# /etc/hadoop/conf/hdfs-site.xml
# /etc/hive/conf/hive-site.xml
# /etc/hbase/conf/hbase-site.xml
# Login as pxf user
su - pxf
# Set the correct Hadoop distro type for generating classpath
# can be one of: cdh, hdp, custom, tar
export HADOOP_DISTRO=custom
# Generate server files
/usr/lib/gpdb/pxf/bin/pxf init
# Edit the /usr/lib/gpdb/pxf/conf/pxf-private.classpath file, be sure it includes
# correct Hadoop libraries for you Hadoop client installation
# Include external JDBC jars in this file
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.151-5.b12.el7_4.x86_64/jre
# Comment the following check in /usr/lib/gpdb/pxf/conf/pxf-env.sh:
# Configured user
#if [ ! -z 'pxf' ]; then
# export PXF_USER=${PXF_USER:-pxf}
#fi
# Start the pxf server
/usr/lib/gpdb/pxf/bin/pxf start
# Check that the server is up
curl "localhost:51200/pxf/ProtocolVersion"
So now, when we have the PXF server running on every Greenplum segment host, we are ready try to access external data sources from Greenplum in parallel.
HDFS data source
Let’s get some data from HDFS. Create a sample flat file with two columns (int and text) separated by comma and put it on HDFS (in the folder /default in this example). Then, create an external table in Greenplum like this:
CREATE EXTERNAL TABLE public.sample_hdfs_ro
(
id int,
sometext text
)
LOCATION ('pxf://default/myflatfile.csv?profile=HdfsTextSimple')
FORMAT 'TEXT' (DELIMITER = E'\,');
Now you can retrieve the contents of the file by selecting the external table. The same way is used to create a HDFS writable external table:
CREATE WRITABLE EXTERNAL TABLE public.sample_hdfs_rw
(
id int,
sometext text
)
LOCATION ('pxf://default/myfolder?profile=HdfsTextSimple')
FORMAT 'TEXT' (DELIMITER = E'\,')
DISTRIBUTED BY (id);
Note that the HDFS path that you specify in the writable external table LOCATION clause is a path to a directory, not to a file. PXF will create files containing data in this directory, and the number of the files is equal to the number of Greenplum segments which have the data. Depending on the distribution of the data and DISTRIBUTED BY clause, the data may be written by all or only few Greenplum segments.
So now you can insert the data from the readable table to the writable one:
insert into public.sample_hdfs_rw select * from public.sample_hdfs_ro;
Hive data source
The next one to get data from is a Hive table. First, create a source Hive external table pointing to our file on HDFS:
--This is Hive SQL code, please run it in Hive --Do not run this code in Greenplum DB CREATE EXTERNAL TABLE default.sample_ext ( id int, sometext string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\,' STORED AS TEXTFILE LOCATION 'hdfs://namenode_host:8020/default/myflatfile.csv';
And now create a usual Hive ORC table and insert the data in it:
--This is Hive SQL code, please run it in Hive --Do not run this code in Greenplum DB CREATE TABLE default.sample_orc ( id int, sometext string ) stored as orc; insert into default.sample_orc select * from default.sample_ext;
Now you can create an external table in Greenplum pointing to the Hive table:
CREATE EXTERNAL TABLE public.sample_hive_ro
(
id int,
sometext text
)
LOCATION ('pxf://default.sample_orc?PROFILE=Hive')
FORMAT 'CUSTOM' (formatter='pxfwritable_import');
You can query the Hive table as a regular Greenplum table.
Hbase data source
The same thing is about Hbase. Let’s create an empty Hbase table in a Hadoop cluster:
--This is Hbase code, please run it in Hbase --Do not run this code in Greenplum DB create 'sample_test', 'basic'
Then create the Hive external table pointing to the Hbase table and insert the data in Hbase:
--This is Hive SQL code, please run it in Hive
--Do not run this code in Greenplum DB
CREATE EXTERNAL TABLE default.sample_hbase(
id int,
sometext bigint
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":id,basic:sometext")
TBLPROPERTIES ("hbase.table.name"="sample_test");
insert into default.sample_hbase select id, sometext from default.sample_orc;
We are ready to create Hbase external table now. If you are reading this line feel free to get in touch with me via email to get personal Hadoop stickers set. Here is the Hbase external table:
CREATE EXTERNAL TABLE public.sample_hbase_ro
(
"basic:key" int,
"basic:sometext" real
)
LOCATION ('pxf://default/sample_test?PROFILE=hbase')
FORMAT 'CUSTOM' (formatter='pxfwritable_import');
That’s it! Now we can query our Hadoop cluster from the Greenplum DB.
JDBC data source (experimental feature)
Good news: Greenplum can query external databases via JDBC connection, and this is not the usual DBlink connection. PXF JDBC works in parallel from all Greenplum segments.
Let’s assume we have:
- An Oracle DB installed and running on host “ora_host”.
- There is a user (=schema) named “gpadmin” with a password “iddqd” in the Oracle DB
- We included the Oracle DB thin JDBC driver in PXF classpath
- The Oracle DB host is accessible from all Greenplum segment hosts
- The ID’s in our sample data are distributed from 1 to 100000 without spaces.
Create a source table in the Oracle DB in gpadmin schema:
--This is Oracle SQL code, please run it in Oracle --Do not run this code in Greenplum DB create table pxf_user.sample_test ( id int, sometext VARCHAR2(100 CHAR) );
And then create the Greenplum external table:
CREATE EXTERNAL TABLE public.sample_jdbc_ora_ro(
id int,
sometext text
)
LOCATION ('pxf://gpadmin.sample_test?PROFILE=JDBC&
JDBC_DRIVER=oracle.jdbc.driver.OracleDriver&
DB_URL=jdbc:oracle:thin:@//ora_host:1521/XE&
PASS=iddqd&
PARTITION_BY=id:int&
RANGE=0:100000&
INTERVAL=5000')
FORMAT 'CUSTOM' (FORMATTER='pxfwritable_import');
The magic of parallelizing the data load is in LOCATION clause. Specifying RANGE and INTERVAL makes PXF generate (RANGE_MAX-RANGE_MIN)/INTERVAL queries in the source database. Each query retrieves its own shard of the data and is executed by a separate Greenplum segement. If the number of shards (=queries) is greater than number of segments in cluster, then some segments will execute more then one query in source database. So we will see in the Oracle DB something like this:
… sdw8 : SELECT id, sometext FROM gpadmin.sample_test WHERE 1=1 AND id >= 85000 AND id < 90000 sdw9 : SELECT id, sometext FROM gpadmin.sample_test WHERE 1=1 AND id >= 95000 AND id < 100000 sdw9 : SELECT id, sometext FROM gpadmin.sample_test WHERE 1=1 AND id >= 90000 AND id < 95000 sdw2 : SELECT id, sometext FROM gpadmin.sample_test WHERE 1=1 AND id >= 45000 AND id < 50000 sdw3 : SELECT id, sometext FROM gpadmin.sample_test WHERE 1=1 AND id >= 60000 AND id < 65000 …
Of course, you should keep in mind that if there is no index on a partition field in the source table, and the table is not partitioned, every query will perform a full scan of the table. In this case, the load process can generate really heavy load on source database.
Partition exchanging
Taking into account all the above, it is important to remember one of another Greenplum features – partition exchanging. It allows you to create complex tables consisting of multiple partitions and each of them can be a regular table or an external table.
One of such scenarios is creating three partitions under one table:
- An external table on source OLTP database containing the latest data;
- A regular Greenplum table for actual data;
- An external partition pointing to a Hive table that contains historical data:
CREATE TABLE public.part_test
(
id int,
sometext text
)
WITH (appendonly=true, ORIENTATION=COLUMN)
PARTITION BY RANGE(id)
(
START (0) END (50) WITH (appendonly=true, orientation=column, compresstype=zlib, compresslevel=5),
START (51) END (100) WITH (appendonly=true, orientation=column, compresstype=zlib, compresslevel=5),
START (101) END (151) WITH (appendonly=true, orientation=column, compresstype=zlib, compresslevel=5)
);
CREATE EXTERNAL TABLE public.part_test_hive
(
id int,
sometext text
)
LOCATION ('pxf://hdfs_schema/part_test?profile=HdfsTextSimple')
FORMAT 'TEXT' (DELIMITER = E'\,');
ALTER TABLE public.part_test EXCHANGE PARTITION FOR (RANK(1)) WITH TABLE public.part_test_hive WITH VALIDATION;
CREATE EXTERNAL TABLE public.part_test_jdbc(
id int,
sometext text
)
LOCATION ('pxf://gpadmin.part_test?PROFILE=JDBC&JDBC_DRIVER=oracle.jdbc.driver.OracleDriver&DB_URL=jdbc:oracle:thin:@//ora_host:1521/XE&PASS=iddqd&PARTITION_BY=id:int&RANGE=101:151&INTERVAL=10')
FORMAT 'CUSTOM' (FORMATTER='pxfwritable_import');
ALTER TABLE public.part_test EXCHANGE PARTITION for (RANK(3)) WITH table public.part_test_jdbc WITH VALIDATION;
These two features make it possible to create complex, flexible and fast data storage models.
Conclusion
PXF makes Greenplum a little more then a database – it is possible now to use Greenplum DB as an effective MPP hub serving all other enterprise systems and providing transactional PostgreSQL-compatible access to all of them. I hope that PXF has a bright future and we will meet a lot of new connectors soon.
